SQL 문법(INDEX, 인덱스)
1. 정의 : 검색 속도 향상을 위해 특정 컬럼에 생성하는 객체로 책의 색인과 같은 기능
2. 인덱스 생성
가. 과 정: 테이블 lock 설정 -> full scan -> 정렬(sort)
나. 생성 대상
– Where 절이나 Join 조건 절에서 자주 사용되는 컬럼
– 전체 데이터 중에서 4~5% 이내의 데이터를 검색하는 경우
– 2개 이상의 컬럼이 where 절이나 join 조건에서 자주사용되는 경우
– 테이블에서 저장된 데이터의 변경이 드문경우
3. 인덱스 작동 원리
사용자의 검색요청 -> dictionary에서 검색 테이블 컬럼의 index 유무 검사 -> 인덱스가 존재할 경우
index에서 데이터 주소 바로검색, 존재하지 않을 경우 테이블 full scan -> 데이터 검색 완료
4. 인덱스 단점
가. DML에 취약
– insert 시에 index split이 발생하여 실행시간을 증가시킨다.
– delete 시에 인덱스의 데이터는 물리적으로 삭제되지 않고 사용불가 마크만 설정된다.
insert, delete가 자주 반복되면 데이터 사용량보다 인덱스 사용량이 더 커질 수 있고 이는 성능저하로 이어진다.
– update 시에는 위에 설명한 insert, delete를 한번 씩 실행한 결과와 동일하며, 가장 성능을 떨어뜨린다.
나. 다른 sql에 악영향
– 오라클의 optimizer는 테이블에 새로운 인덱스가 생성되면, 기존에 사용하던 테이블의 인덱스 대신 새로운 인덱스를
사용하여 sql을 실행한다. 만약 새로운 인덱스가 기존의 인덱스에 비해 효율적이지 못하다면, 오히려 기존의 sql의
실행시간이 길어지게 된다. 인덱스 생성은 심사숙고할 필요가 있다.
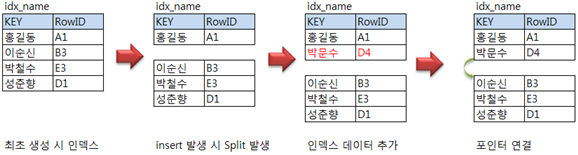
참고 : index split
최초 인덱스 생성 시 인덱스는 연결된 블록에 모여 저장되어 있으나, 데이터의 insert 발생 시 인덱스의 저장공간이 쪼개지는
것을 말한다. 테이블에 insert가 발생하게되면 1차적으로 인덱스 정보를 추가하고, 테이블에 실제 데이터가 추가된다. 이때
인덱스는 새로운 인덱스가 들어갈 위치를 기점으로 하여, 2개로 쪼개지는데 이 과정에서 성능저하가 일어난다.
5. 인덱스의 종류
가. 고유 인덱스 : 유일한 값을 가지는 컬럼에 대해 생성(가장 성능이 좋은 인덱스)
나. 단일 인덱스 : 하나의 컬럼으로 구성된 인덱스
다. 결합 인덱스 : 두개 이상의 컬럼으로 구성된 인덱스
예)
select …. from emp where deptno=100 and sal > 5000;
create index index_name on emp(deptno, sal);
참고 : 결합인덱스의 경우 컬럼의 순서
결합인덱스의 경우 컬럼의 순서에 따라 sql 실행속도에 영향을 주며, 가장 적은 비용을 들일 수 있는 방법을 찾아서 선택해야한다.예) 총 30명(남자 25, 여자 5명)의 사람 중에서 빨간펜 들고 있는 남자가 1명 있을 경우 빨간펜 검색
(성별, 빨간펜 여부) 보다 (빨간펜 여부, 성별)순으로 결합인덱스를 구성하는 것이 성능이 뛰어나다.설명)
(성별, 빨간펜 여부)로 인덱스를 생성할 경우의 최종검색 소요비용 :55
1차 : 성별여부 확인을 위해 30명 정렬 실행 (실행비용 : 30)
2차 : 25명의 남자중 빨간펜 보유여부 확인 (실행비용 : 25)
———————————————————————
(빨간펜 여부, 성별)로 인덱스를 생성할 경우의 최종검색 소요비용 : 31
1차 : 빨간펜 여부 확인을 위해 30명 정렬 실행 (실행비용 : 30)
2차 : 성별 여부 확인 (실행비용 : 1 )만일 위 예제에서 여자중에서 빨간펜을 가지고 있는 사람을 검색하거나, 빨간펜을 가지고 있는 사람이 다수일 경우 실행비용은 달라질 수 있으며, 실행비용의 크기가 역전되어 인덱스의 순서를 바꿔야 할 수도 있다.
라. descending 인덱스 : 큰 값을 먼저 검색하는 경우 사용
예) 최근날짜를 먼저 출력하는 은행계좌
마. 함수 기반 인덱스(FBI, Function Based Index) : 사용하지 않는 것을 권장
참고 : 함수 기반 인덱스에서의 연산
인덱스가 생성된 컬럼을 where 절에 사용할 경우 사칙연산, 함수 등을 수행하지 않도록 한다
이 경우 해당컬럼이 인덱스가 생성되어 있더라도, 인덱스를 사용하지 않게 된다.예) create index index_name on emp(sal);
select … from … where sal > 1000; <– 인덱스 사용
select … from … where sal+100 > 1000; <– 인덱스 미사용
select … from … where sal > 900; <– 수정, 인덱스 사용
6. 인덱스 재구성
가. rebuild : 인덱스 상태가 좋지 않을 때 불필요한 인덱스 데이터를 삭제 및 정리
나. 삭제 후 생성 : 인덱스 상태가 심각하게 좋지 않을 때, 기존 인덱스를 삭제하고 새로 생성

최신 댓글